Les principes et l'architecture
Au fil des ans, trois grands principes ont émergé qui ont façonné le domaine de la gestion de données (voir la figure ci-dessous) :
Abstraction : Un système de gestion de bases de données sert de médiateur entre des individus et des machines. Pour mieux s'adapter aux individus, il doit organiser et présenter les données de façon intuitive et permettre de les manipuler en restant à un niveau abstrait sans avoir à considérer des détails d'implémentation.
Indépendance : nous distinguons trois niveaux, physique, logique et externe, que l'on essaie de rendre le plus indépendants possible. Au niveau externe, nous trouvons les vues d'utilisateurs particuliers qui partagent la base de données. Chaque vue est adaptée aux besoins de l'utilisateur. Au niveau logique, nous trouvons une organisation unique des données typiquement dans le modèle relationnel que nous détaillons plus loin. Et au niveau physique, les détails de l'organisation sur disque et de structures comme des index dont le rôle est d'accélérer les calculs. Le but est de pouvoir modifier un niveau (par exemple, ajouter un nouvel utilisateur avec de nouveaux besoins) sans modifier les autres niveaux.
Universalité : Ces systèmes visent à capturer toutes les données d'une entreprise, d'un groupe, d'une organisation quelconque, pour tout type d'applications. Il leur faut donc offrir des langages de développement d'applications puissants et une gamme de fonctionnalités très riche. Des limites de cette universalité existent aujourd'hui pour les systèmes relationnels : énormément de données moins structurées sont par exemple gérées dans des systèmes de fichiers.
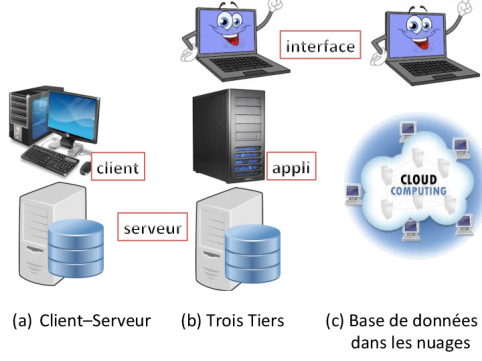
Mentionnons brièvement les architectures les plus répandues de systèmes de gestion de données. Une première architecture est celle des systèmes client/serveur. La base de données est gérée sur un serveur. L'application tourne sur une autre machine, le client. De plus en plus, cette architecture se complique avec l'introduction d'un troisième “tiers” (ce qui signifie en réalité “niveau” en anglais), une machine qui gère l'interface, typiquement un navigateur Web sur une tablette ou un laptop.
Nous pouvons noter différentes évolutions générées par des améliorations dans les matériels disponibles :
l'accroissement des performances notamment fondées sur les mémoires vives de plus en plus massives, et des mémoires flash encore plus massives ;
l'utilisation de plus en plus de parallélisme massif dans des grappes de machines pour traiter d'énormes volumes de données. On parle parfois de “big data” ;
pour simplifier la gestion de données, on tend à la déporter dans les nuages (le cloud), c'est-à-dire à mettre ses données dans des grappes de machines gérées par des spécialistes comme Amazon.