ARNm
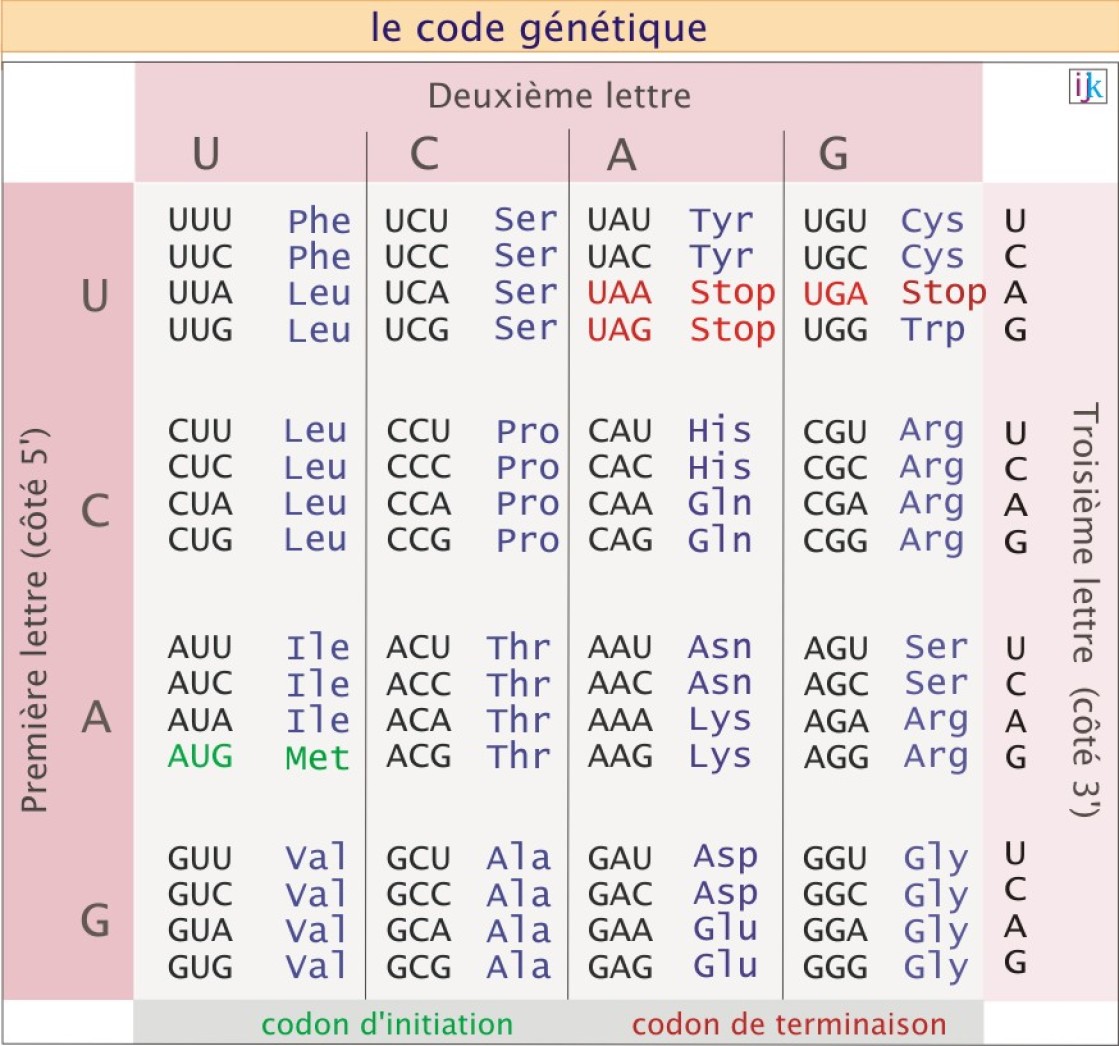
La synthèse des protéines, au contraire de la synthèse lipidique et de l'assemblage des chaînes glucidiques, est dirigée par une matrice. Cette matrice, l'ARN messager (ARNm) déterminera, grâce à un message codé, la nature, l'ordre et le nombre des acides aminés (parmi un choix de 20 différents), assemblés pour former l'axe polypeptidique de la protéine. Dans ce code, déchiffrable uniquement dans le sens 5' vers 3', l'identité de chaque acide aminé est donnée par une séquence spécifique de trois nucléotides consécutifs sur l'ARNm, dénommée codon. Les nucléotides du code sont au nombre de quatre : adénine phosphate (A), guanosine phosphate (G), cytosine phosphate (C) et uridine phosphate (U).
Exemple : AUG code la méthionine, ACC code la thréonine et UCA code la sérine (voir figure 3).
Complément : Partez en excursion : Sanger et la reconnaissance de l'importance d'une séquence amino-acidique orientée
On savait que les protéines étaient constituées de 20 acides aminés différents, mais jusqu'en 1955, on n'a pas attaché d'importance à l'ordre dans lequel ils étaient enchaînés les uns aux autres et l'opinion la plus répandue était que leur arrangement était le fruit du hasard. Charles Chibnall, professeur de biochimie à Cambridge, Royaume Uni, suggérait au contraire que cet arrangement était défini et précis. Chibnall tenta d'obtenir des fonds auprès du Medical Research Council pour l'un de ses étudiants, Frederick Sanger, particulièrement intéressé par la question. La demande fut rejetée car, lui fut-il répondu, « chacun sait » que les acides aminés d'une protéine sont arrangés au hasard. Néanmoins, Sanger commença le travail en choisissant l'insuline comme modèle, excellent choix étant donné sa taille (51 acides aminés) et son importance clinique. Il lui fallut 10 ans (1945-1955) pour élucider la séquence complète des deux chaînes polypeptidiques qui constituent l'insuline (voir figure 29). Ce faisant, il était le premier à séquencer une protéine entière et démontrait ainsi que l'ordre des acides aminés n'est pas le fruit du hasard. Deux prix Nobel de Chimie récompensèrent Sanger, l'un pour son travail sur la structure des protéines (1958) et l'autre, plus tard (1980 partagé avec Walter Gilbert et Paul Berg), sur l'élucidation de séquences de bases dans l'ADN (sujet non évoqué ici).

Comme on le voit dans la figure 3, l'ensemble des codons possibles, 43 = 64, est supérieur au nombre d'acides aminés disponibles (20 chez les Eucaryotes), si bien qu'un même acide aminé peut être codé par plusieurs codons : si le tryptophane n'a que le seul codon UGG, la glycine peut être codée par les combinaisons GGU, GGC, GGA ou GGG. Pour faire référence à cette caractéristique, les anglo-saxons parlent de « degenerate code ».
Etant donné qu'on dispose de 20 acides aminés, le code à trois lettres paraît être le plus cohérent (optimum). En effet, le code à deux lettres serait insuffisant, car ne permettant que 16 combinaisons (42). A l'inverse, le code à quatre lettres, permettant 256 combinaisons (44) serait excessif, rendant inutilement long le génome codant. Le code est universel : il est utilisé par tous les organismes, animaux, végétaux, champignons, bactéries et virus. Cependant, des codons légèrement différents peuvent exister chez les mitochondries et certaines bactéries.

Chez les Eucaryotes, le message codé porté par l'ARNm a lui-même été copié par une ARN polymérase–II nucléaire lors d'un processus appelé transcription, sur une séquence nucléotidique précise faisant partie de l'ADN du noyau et qu'on appelle gène (copie complémentaire du brin non codant du gène, voir figure 4). Le séquençage du génome humain a démontré l'existence d'environ 20 500 gènes (qui ne représentent que 1,5% de la quantité totale de l'ADN du noyau). Il est important de savoir que ces 20 500 gènes sont à l'origine de la synthèse d'environ 200 000 protéines différentes (amplification). Comme nous le verrons dans la ressource « transcription et réplication de l'ADN », c'est l'épissage (alternatif), traitement différentiel du transcrit primaire de l'ARNm ou ARN hétérogène nucléaire (ARNhn, copie brute du gène), qui est largement responsable de ce phénomène d'amplification (voir figure 5).

En bref, l'ARNhn subit des modifications qui consistent dans le rajout d'une tête côté 5' (7–méthyl–guanosine–triphosphate ou m7G), dans l'élimination des introns, séquences non codantes de l'ARNm (phénomène d'épissage) et enfin, dans l'addition d'une chaîne d'environ 200 adénosines coté 3' (queue poly (A)). Dans des cas particuliers, l'élimination de certains exons, séquences codantes de l'ARNm, conduit à un phénomène appelé épissage alternatif. L'ARNm ainsi maturé (environ la moitié de la taille du transcrit primaire) se complexe avec des protéines, les protéines ribonucléiques hétérogènes. C'est le cas des facteurs d'initiation eIF4E et eIF4G, ainsi que des protéines fixant le poly (A) (PABP 1 et 2, poly (A) binding protein) (voir figure 6 et . L'ensemble quitte le noyau à l'aide de la protéine p15 liée à TAP (Tip-Associated Protein) qui participe au transport à travers le pore nucléaire. En sortant du noyau, l'ARNm est tout de suite reconnu par d'autres facteurs d'initiation (eIF's) de la synthèse protéique comme on le décrira ci-dessous. La présence de la tête 5' (m7G), la queue poly(A) et les protéines qui fixent ces structures, empêchent l'accès des exonucléases à la chaîne nucléotidique et augmentent ainsi la durée de vie de l' ARNm. Dans la plupart des \ARNm il existe des éléments riches en AU, les AREs positionnés coté 3', qui eux aussi fixent des protéines impliquées dans la régulation de la durée de vie (de quelques minutes à quelques jours selon l'ARNm, sa qualité et le contexte cellulaire) (voir figure 6, et ).

![]()
Macromedia Flash - 283Ko
![]()
Macromedia Flash - 285Ko
Complément : Excursion : découverte du code génétique
En 1958, Francis Crick (Medical Research Unit au Cavendish Laboratory, Cambridge, Royaume Uni) proposa deux principes pour expliquer le passage de l'information de l'ADN à la protéine : « l'hypothèse de la séquence » et « le postulat central ». Ces deux principes sont aujourd'hui acceptés comme doctrine de la biologie moléculaire. L'hypothèse de la séquence dit que la spécificité d'un segment donné d'acides nucléiques est représentée uniquement par la séquence des bases qui le constituent et que cette séquence renferme une indication codée sur la nature, l'ordre et le nombre des acides aminés (de la protéine). Le deuxième principe propose que l'information passe de l'acide nucléique à un autre acide nucléique (transcription et réplication) et également de l'acide nucléique à la protéine (traduction) mais jamais de la protéine à la protéine ou de la protéine à l'acide nucléique (sens unique). Une fois admise l'idée que la séquence d'ADN dicte d'une façon ou d'une autre la composition de la protéine, la question suivante qui surgissait était : quel est le lien entre la séquence nucléotidique de l'ADN (ou de l'ARN) et celle des acides aminés de la protéine ? Cette question de la recherche d'un « code génétique » fut le sujet d'une collaboration dans les années 60 entre Francis Crick, Sydney Brenner, Leslie Barnett et Richard Watts-Tobin. Dans une longue série d'expérimentations complexes, ils induisirent, grâce au mutagène proflavine, des mutations dans l'ADN du bactériophage T4 (un virus qui infecte les bactéries). La proflavine change la composition de l'ADN du bactériophage par insertion ou délétion d'un ou plusieurs nucléotides. L'insertion de l'ADN viral dans l'ADN de bactérie se traduisait par un décalage dans la séquence normale et résultait en l'apparition d'une séquence protéique nouvelle, qui supprimait ou non la fonction de la protéine virale : la protéine devenait inactive quand il y avait insertion d'un seul nucléotide mais retrouvait son activité quand l'insertion était doublée d'une délétion. L'interprétation de ce phénomène est donnée par la figure ci-dessous. Une addition de A entraîne la traduction d'une protéine aberrante à cause d'un décalage de phase (frameshift). Lorsqu'elle survient dans un deuxième temps, la délétion en compensant l'addition précédente, remet l'ensemble en phase et permet la traduction d'une protéine peu modifiée et encore fonctionnelle.
Message original : bien que ce message soit écrit sous forme de triplet, il faut être conscient qu'à l'époque, les expérimentateurs ignoraient que chaque acide aminé était représenté par un triplet (code génétique).

Message muté (une insertion) : toute la séquence post mutation est « hors phase » et code de nouveaux acides aminés erronés (x).

Message muté (une insertion + une délétion) : deux acides aminés erronés (x), puis retour en phase.

Par la suite, ils effectuèrent plusieurs délétions superposées et trouvèrent que l'activité de la protéine ne pouvait être restaurée qu'avec trois délétions, deux ou quatre délétions étant néfastes. Ils conclurent donc que l'identité d'un acide aminé était déterminée par un codon de trois nucléotides successifs.

Parce qu'ils obtenaient presque toujours une protéine traduite après les diverses mutations, leur travail suggéra aussi que le code n'était pas strict (« dégénéré », qualifié de « degenerate » par Crick), ce qui veut dire que chacun des 64 triplets de nucléotides possibles (43) a une signification dans le code génétique. En effet, si pour les 20 acides aminés, 20 triplets seulement avait été attribués, il est hautement probable que les mutations expérimentales évoquées ci-dessus n'auraient pas permis la traduction d'une chaîne amino acidique après la mutation (étant donné que 44 triplets n'auraient eu aucune signification).
« Crick F H C, Barnett L, Brenner S, Watts-Tobin R J. General nature of the genetic code for proteins. Nature 192 : 1227-1232. 1961 »
Plus tard, il apparut que le code génétique possédait trois triplets ne codant pas des acides aminés mais servant à marquer la fin du message : codons stop. Dans les années 1960, Marshall Nirenberg ainsi que d'autres équipes élucidaient le code dans un système artificiel (cell-free) de synthèse protéique avec des \(\rm ARNm\) synthétiques constitués d'une répétition de tous les triplets possibles (UUU UUU UUU, AUU AUU AUU etc.)